JustinDB - solving data entropy: Active-Anti Entropy
Preface
In previous post I wrote what data entropy is and how JustinDB tries to solve it. I’ve introduced to you also Read-Repair technique and gave quick intro to todays hero - Active Anti-Entropy. 💪
We know that Read-Repair is triggered on read side, rather than a write. But what if read some data very rarely? It can be eventually be lost! To handle this and other threats to durability, JustinDB implements mentioned an anti-entorpy (replica synchronization) protocol to keep the replicas synchronized.
Active-Anti Entropy (AAE)
So AAE is nothing more like a synchronization protocol to handling permanent failures. JustinDB supports it to proactively identify and repair inconsident data. This feature helps to recover data loss in the event of disk corruption or administrative error.
To detect inconsistencies between replicas faster and to minimize the amount of transferred data, JustinDB uses Merkle Trees. Its a sophisticated hash tree which makes it easy to compare data sets between vnodes.
Merkle Trees
Merkle Trees is a hash tree where leafes are hashes of the values of individual keys. Parent nodes are hashes of their respective children.
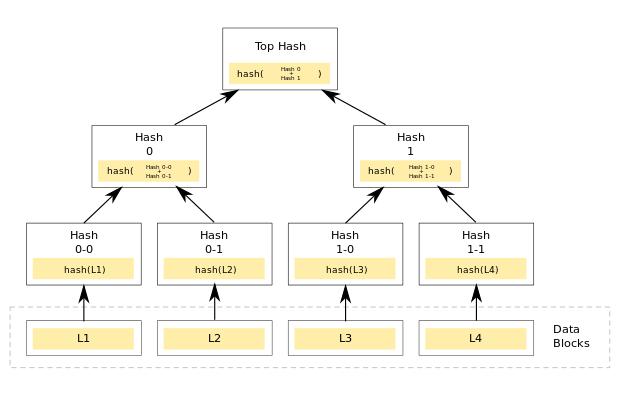
They minimize the amount of data that needs to be transferred for synchronization.
Each vnode maintains a separate Merkle Tree for each key range it hosts. If the hash values of the root of two trees are equal, then there is no point in doing synchronization since its meaning that leaf nodes are equal (replicas are the same). If not, it implies that the values of some replicas are different and they need to be synchronized.
Since this process can be a bit expensive (think about existing many divergent replicas or just about profilactic checking of hashes throughout all cluster) its triggered manually by database administrator (e.g every friday night). ✌️